Große Datensammlungen (Big-Data) bieten Unternehmen die Chance, Kunden die für sie gerade relevanten Daten zu liefern. censhare baut diesen Ansatz mit der Version 4.8 aus. Es lassen sich Kontext-Informationen wie Interessensgebiete oder Empfehlungen für ein Thema gewichten.
Relevante Informationen aus der Datenflut anbieten
Das aktuelle Stichwort Big-Data beschreibt die Herausforderung der Unternehmen, sehr schnell wachsende Datenmengen zu speichern und für ihr Geschäft zu nutzen. Über Context-Aware-Computing können sie ihren Kunden aus den verfügbaren Daten, die für sie in ihrer Situation relevanten Informationen anbieten. Mit censhare lassen sich Daten für Context-Aware-Computing speichern und auswerten.
Dabei gilt, je mehr ein Nutzer über seine aktuelle Situation (Kontext) wie seine Interessensgebiete zur Verfügung stellt, umso besser kann die Auswahl sein. Diese werden Daten dann gespeichert und miteinander verknüpft. Es entsteht ein Netzwerk, das mit jeder weiteren Information zum Anwender wächst. Dieses digitale Abbild ist dann die Basis, um den Nutzer automatisch möglichst passende Inhalte, Dienstleistungen, Produkte oder anderes anzubieten. Mit der Version 4.8 erweitert censhare die Kontextinformationen um eine Gewichtung der Daten. Dadurch lassen sich deren Bedeutung und die Zusammenhänge zwischen diesen noch besser beschreiben und berücksichtigen.
Mit solchen Informationen ist es beispielsweise deutlich einfacher, einem Anwender bei einer Suche für ihn relevante Treffer anzubieten. So kann ein Unternehmen die Beschreibungen seiner Bücher mit Schlagwörtern versehen. Da nicht alle Begriffe gleich relevant sind, bekommen diese noch eine zusätzliche Gewichtung. Eine Reiseerzählung über die Flucht eines Jungen durch Irland im 19. Jahrhundert könnte unter anderem folgende Tags erhalten: Roman (100 Prozent), Abenteuer (90 Prozent) und Reisen (70 Prozent). In censhare lässt sich dafür ein Objekt beziehungsweise Asset mit Stichwörtern versehen, die eine Gewichtung in Prozent bekommen. Sucht ein Nutzer nun nach Romanen, landet das Buch in der Trefferliste deutlich weiter vorne, als wenn es um Reisen ginge. Neben Stichwörtern lassen sich Objekte in censhare aber auch um andere Eigenschaften flexibel ergänzen. So könnte das obige Buch noch die Zielgruppen Jugendliche (100 Prozent) und junge Erwachsene (50 Prozent) bekommen.
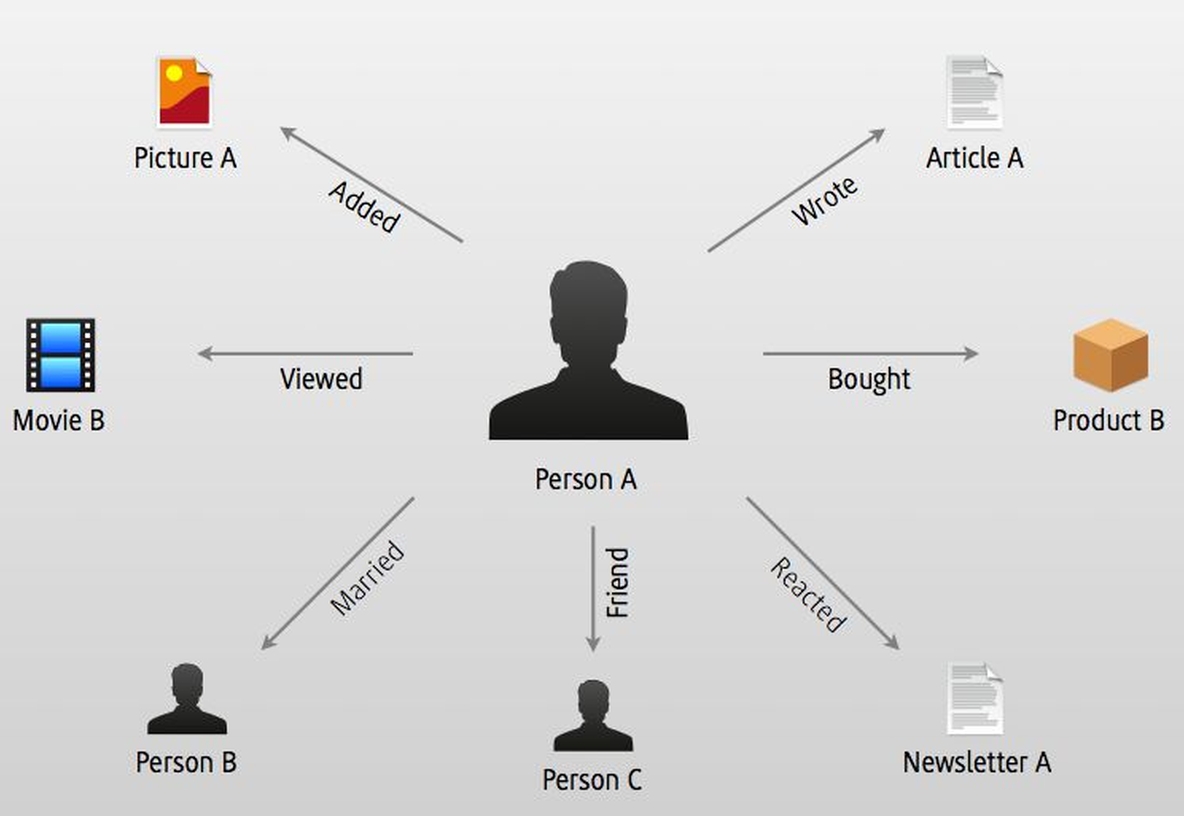
Neben der Verbesserung des Einkaufserlebnisses im Web bietet sich Context-Aware-Computing beispielsweise dafür an, in Abhängigkeit vom Medienkanal und Aufenthaltsort entsprechende Informationen zu liefern. Ist ein Anwender mit seinem Smartphone unterwegs, interessieren ihn andere Daten als zuhause beim Surfen im Internet. censhare bildet die Basis, um neben den eigentlichen Informationen auch den Kontext zu erfassen.
Dies können Sensor-Informationen wie Zeit oder Ort, Eigenschaften wie Alter oder Unternehmen, Beziehungen zu anderen Personen oder historische Daten sein. Letzteres sind beispielsweise Kaufaktionen oder gelesene Artikel. censhare speichert diese Informationen als Objekte mit Eigenschaften und setzt sie über Verknüpfungen miteinander in Beziehung, beispielsweise Nutzer und Interessensgebiete. Die Verknüpfungen und Eigenschaften können zusätzlich noch eine Relevanz bekommen.
Damit bilden Objekte, Eigenschaften, Verknüpfungen und Relevanz zusammen in censhare ein umfassendes Datenmodell, um die Wirklichkeit mit ihren Zusammenhängen abzubilden. Es lassen sich sowohl Informationen als Nutzer umfassend in ihrem jeweiligen Kontext beschreiben. Unternehmen können über dieses Modell einen möglichst großen Nutzen aus den verfügbaren Daten ziehen.
Kunden-Nutzen
Speichern und Verarbeiten großer Mengen an unstrukturierten Daten beziehungsweise Informationen
Entwickeln von Kontext-abhängigen Applikationen (Context-Aware-Computing)
Umfassendes Datenmodell mit Objekten, Eigenschaften, Verknüpfungen und Relevanz, um Informationen möglichst gut zu speichern und zu nutzen
Definition von Objekten wie Anwender, Unternehmen oder Produkte mit ihrem Umfeld (Kontext)
Auswahl der passenden Daten beziehungsweise des Contents in Applikationen in Abhängigkeit vom Kontext des Nutzers und der Anwendung
Abbilden von komplexen und unstrukturierten Daten mit dem Datenmodell von censhare, wie sie bei Big-Data und Context-Aware-Computing vorkommen
Definition der Relevanz einer Information wie Stichwörter, Zielgruppen, Geo-Koordinaten oder Kategorien für ein Objekt
Gewichtung der Ergebnisse einer Suche nach bestimmten Eigenschaften oder Verknüpfungen mithilfe der zugehörigen Relevanz
Verknüpfen verschiedener Datenbank-Ansätze (NoSQL) für die Arbeit mit großen, unstrukturierten Datenmengen (Big Data)
Kombination der Vorteile von relationalen und NoSQL-Datenbanken ohne deren Nachteile
Skalierbare Architektur für den Einsatz bei großen Datenmengen und einer großen Anzahl von Nutzern
Anwendungsfall
Entwickeln und Bereitstellen von Content-Applikationen, die Nutzer, ihre Interessen, die Sprache, das Gerät oder den Ort berücksichtigen
Unterschiedliche Darstellung und Umfang des Contents in Abhängigkeit vom verwendeten Gerät wie Laptop, Tablet oder Smartphone
Personalisierung des Contents für verschiedene Zielgruppen anhand der Daten des Nutzers wie Interessen, Beruf oder Alter
Alles, um die reale Welt zu speichern
Für die Speicherung von unstrukturierten, großen Mengen an Daten (Big-Data) wie sie etwa für Context-Aware-Computing anfallen, eignen sich relationale Datenbanken nicht. censhare verwendet daher ein Graphenmodell, bei dem Objekte wie Personen, Sensordaten oder Unternehmen über Beziehungen miteinander verknüpft sind. Durch die Relevanz-Eigenschaft wird dieses Datenmodell weiter verfeinert. In einer Antwort zu einer Suche werden die Ergebnisse mit einer höheren Relevanz weiter vorne angezeigt. Das Graphenmodell ist auch einer der Ansätze, den NoSQL-Datenbanken (Not-only-SQL) verwenden. Diese haben durch das Thema Big-Data als Alternative zu relationalen Datenbanken an Bedeutung gewonnen.
Dokumente sind ein Teil der unstrukturierten Informationen, wie sie bei Big-Data vorkommen. XML eignet sich sehr gut, um die Informationen in diesen Dokumenten zu beschreiben. censhare kann auch diese Art von Daten entsprechend speichern und verarbeiten. Es verwendet XML zur Beschreibung von Dokumenten und den internen Strukturen. Über XSLT (XSL-Transformationen) lassen diese Informationen automatisch verändern. Dokumenten-Datenbanken, die ebenfalls zu den NoSQL-Datenbanken gehören, basieren ebenfalls auf XML.
Zu den Herausforderungen von Big-Data gehört es auch, die vorhandenen großen Datenmengen quasi in Echtzeit zu durchforsten und Antworten zu liefern. Mithilfe einer selbst entwickelten Datenbank kann censhare in Sekunden seine Datenbestände abfragen. Die Datenbank verwendet dazu den Key-Value-Ansatz, der in einer Zeile immer nur einen Schlüssel und den zugehörigen Wert enthält. Der Key-Value-Ansatz kommt auch bei NoSQL-Datenbanken zum Einsatz.
NoSQL-Datenbanken sind jedoch eine relativ junge Technologie. Deshalb sind sie in vielen Bereichen noch nicht so ausgereift wie relationale Datenbanken. censhare ist es gelungen, aus beiden Welten das Beste miteinander zu verbinden. Für die Arbeit mit den großen Datenmengen (logische Datenbankschicht) verhält es sich wie eine NoSQL-Datenbank. Die physikalische Speicherung erfolgt jedoch in einer relationalen Datenbank mit allen Vorteilen wie Transaktionssicherheit oder ausgereiften Backup- und Archivierungstools. Aber censhare hat nicht die Probleme, wie sie sich bei relationalen Datenbanken aufgrund ihres logischen Datenmodells für den Big-Data-Einsatz ergeben. Hier ähnelt es eben NoSQL-Datenbanken.
Ganz nah an der realen Welt
Im Datenmodell von censhare repräsentieren Assets die Objekte. Kompliziertere Objekte wie ein Reiseland lassen sich durch Assets zusammenfügen. Beispielsweise könnte sich Irland aus Regionen zusammensetzen. Diese können Sehenswürdigkeiten oder interessante Städte besitzen. Städte wiederum haben ebenfalls Sehenswürdigkeiten. Die verschiedenen Assets sind über gerichtete Links miteinander verknüpft, denen sich auch folgen lässt. Einem Asset lassen sich auch verschiedenste Informationen von Texten, Bildern, Ton oder Videos zuordnen.
Ein Nutzer liest einen Beitrag zu einer Sehenswürdigkeit einer bestimmten Stadt. Nun will er etwas zu weiteren Sehenswürdigkeiten der Stadt erfahren. Ausgehend vom aktuellen Artikel findet censhare das Objekt der zugehörigen Stadt. Von dort aus kann censhare dann den Links zu allen Sehenswürdigkeiten folgen, die mit der Stadt verknüpft sind, und diese dem Nutzer anbieten. Der Vorteil dieses Suchansatzes ist, dass die Antwortzeit nicht vom gesamten Datenbestand, sondern nur von der Größe des Ergebnisses abhängt. In diesem Fall ist das die Anzahl der Sehenswürdigkeiten für die aktuelle Stadt und nicht alle Sehenswürdigkeiten.
Das Datenmodell in censhare ist sehr flexibel und lässt sich einfach erweitern, ohne die bisherige Struktur ändern zu müssen. Mit der Relevanz fügt censhare dem Datenmodell eine weitere optionale Eigenschaft hinzu. Sie lässt sich im Admin Client sehr einfach über ein Häkchen im entsprechenden Eigenschafts- beziehungsweise Verknüpfungsdialog aktivieren. Im obigen Beispiel könnte es die Beliebtheit einer Stadt oder Sehenswürdigkeit darstellen. Wenn der Nutzer nach weiteren Sehenswürdigkeiten einer Stadt sucht, kann censhare die Ergebnisse nach ihrer Relevanz ordnen. In diesem Fall bekommt der Anwender die Ergebnisse nicht in alphabetischer Reihenfolge, sondern nach der Beliebtheit der Sehenswürdigkeiten geordnet angezeigt. Die interessantesten Orte stehen also ganz vorne in der Liste.
Nach der Aktivierung kann der Anwender im Dialog für die Eigenschaften (Metadaten) eines Objekts (Assets) einen Wert hinter der zugehörigen Eigenschaft eintragen. Standardmäßig beträgt dieser 100 Prozent.
Mit diesem Datenmodell ist censhare sehr gut aufgestellt für Anwendungen im Bereich Big Data beziehungsweise Context-Aware-Computing. Unstrukturierte Daten, wie sie häufig bei Big Data vorkommen, lassen sich gut abbilden.