Persistent data structures got a boost because using locks for synchronizing access to data proved to be error prone and cumbersome. We are not talking about database persistence here, but instead about immutable data structures that provide a type of copy-on-write semantics to allow for concurrent reads while performing concurrent data updates (see and ).
Persistent data structures got a boost because using locks for synchronizing access to data proved to be error prone and cumbersome. We are not talking about database persistence here, but instead about immutable data structures that provide a type of copy-on-write semantics to allow for concurrent reads while performing concurrent data updates (see http://en.wikipedia.org/wiki/Persistent_data_structure and http://de.wikipedia.org/wiki/Copy-On-Write).
Whereas implementations of "real" copy-on-write data structures like http://docs.oracle.com/javase/6/docs/api/java/util/concurrent/CopyOnWriteArrayList.html actually perform an expensive data copy, there are some solutions that only copy a minimum amount of data. Most of them use tree based structures that create a new tree with a new root node referencing unchanged nodes of the "old" tree thus reusing existing data without creating a full copy of the previous version. The ZFS file system or the PersistentHashMap of the Clojure programming language works that way for example.
I was looking for an ordered set and map data structure and algorithm for long keys and values supporting concurrent reads by multiple threads and updates by a single thread.
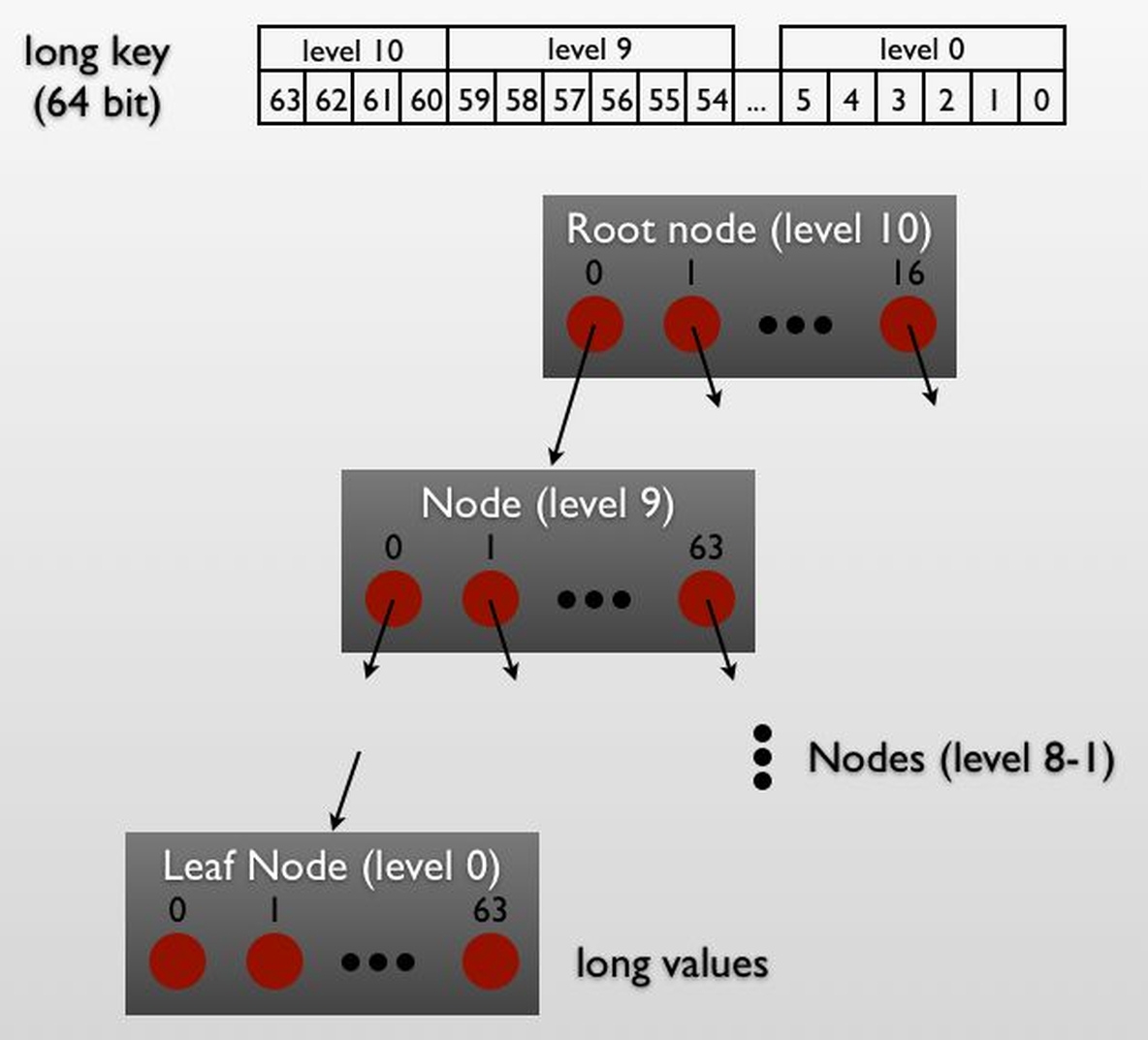
The idea starts with a n-ary tree. Instead of storing keys inside the nodes as in B-trees for example (see http://en.wikipedia.org/wiki/B-tree) the value of the long key is split into bit groups and the group value is used as an index to the child pointer. A 64-ary tree can store 6 bits (2^6 = 64) per level. Since a long itself has 64 bits, we need 11 levels including the root node (11*6 >= 64) in the tree. So the node position in the tree defines the key with which it is associated. Such a data structure is called trie (see http://en.wikipedia.org/wiki/Trie).
Storing 64 child pointers in each node would waste a lot of space but there's a trick: Only the non-empty child-pointers are stored and a bit-array is used to note which ones are non empty. Again a long is used to store that bit array providing 64 bits which explains why our tree is 64-ary.
At first glance it looks like accessing this structure will require some expensive and nasty bit juggling. Fortunately this isn't the case:
The first line extracts the 6-bit group corresponding to the level from the key and calculates the bit-positing in our bit-array. If not set, our trie doesn't contain that key (return false). Otherwise we need to know the number of non empty child pointers to get the index in our pointer array. This is the number of set bits below our "target" bit which is what the last line calculates.
Everything so far is done using only a few operations and will deliver a good performance. But what about Long.bitCount? If you look at the java source code this is calculated using some tricky and efficient bit manipulation as well (see http://en.wikipedia.org/wiki/Hamming_weight). But it gets even better: Since java version 1.6.0_18 Long.bitCount is a so called intrinsic: The compiler directly uses the corresponding machine instruction if available (see http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=6378821).
Instead of using java objects to represent nodes, let's try to store the complete tree in one long[] for better space and time efficiency. The java garbage collection would be happy as well because the GC times are primarily related to the number of objects in the heap and not to the amount of memory used. Each node is stored as consecutive longs - the bitmap followed by the child pointers - and each child pointer is the index of the long[] to the start of the child node. In addition our trie stores the index of the root node.
The drawback of using a long[] is that we have to implement our memory management by ourselves. For updates we may have to insert a new child pointer into a node which requires more space. Here we can use the classic approach: Allocate a larger than required long[] and append a replaced node at the end of the used space, collecting the space of the replaced node in a free list. If all spaces is used up or too fragmented to provide the requested space, we copy the long[] to a newly allocated larger one and maybe even compact (defragment) it on the fly during the copy.
How does the copy-on-write semantics with multiple concurrent reading threads and a single writing thread work? The updating thread creates a shallow copy of the trie referencing the same long[] but with its own root pointer. After performing the update(s) it replaces the trie reference the reading threads are using.
Now the idea with the free lists has been good but doesn't work since we cannot override existing nodes as long as they maybe still in use by readers. However we know that nodes created by and later replaced by the updating thread can be recycled since only the writer knows about them. This is done by using a generation counter that increases when an updating thread creates a shallow copy. The generation of a changed node is stored together with each child pointer: Since we use longs and need only an int (32 bit) for the index into our long[] we have 32 bits unused anyway. Of course this optimization only makes sense if the updating thread performs multiple updates in one "transaction". But if it does, this strategy vastly reduces the number of compactions and expansions.
Add, contains and remove operations have a constant time complexity - O(1) - if no compaction or expansion takes place. Albeit the constant time factor may be high: We have 11 levels and for each level an insertion may have to copy 64 longs as worst case. Nevertheless the time complexity of the operations is not dependent on the number of stored keys.
The complete source code for a map and set can be found here. The set uses a slightly optimized data structure that "inlines" the leaf nodes - which only contain a bit-array - instead of having separate nodes referenced by child pointers.
Now what are these things good for? One application is an inverted index used in text search engines: For each term an inverted index stores a list of document IDs that contain that term. The same may be applied to meta-attribute-values. This can be implemented using the set implementation. For some relevance/ranking algorithms, the term frequency (number of occurrences of that term in the document) and the document size has to be maintained as well. This is where the map implementation comes into place.
Since the nodes are maintained in "bit-order" its possible to create an iterator delivering the IDs in order which allows the use of a merge-join (see http://en.wikipedia.org/wiki/Sort-merge_join) to implement the typical set operations (union, intersection, difference) required to implement "and" "or" and "not" query expressions. Even a "skip" method is possible to "fast forward" to the next target key to improve the performance of intersection and difference expressions. This will be the topic of one of the next blog entries.
Walter Bauer ist einer der Gründer der censhare AG und leidenschaftlicher Software-Designer und -Programmierer mit einem Spleen für Performance-Optimierungen und Refactoring.